Refactoring vs Rewriting from Scratch: Which to Choose When You Have Technical Debt?
June 12, 2026
Oleksandr Sheiko | Software Developer at SDA

Refactoring is the safer default in most cases. A full rewrite is justified only when the architecture, technology stack, or scalability limits make incremental improvement unrealistic.
This article walks through how to make this decision based on measurable signals - not gut feeling - and covers refactoring, full rewrites, and the Strangler Fig pattern as a middle path.
What is technical debt and why does it accumulate?
Technical debt is the accumulated cost of development shortcuts. Deadlines, rushed features, skipped tests - each adds a little complexity. Over time, that complexity slows down new features, debugging, and onboarding new developers.
Debt comes in four types:
- Code debt: poorly written functions, duplication, missing tests
- Architectural debt: bad system-level decisions (e.g. a monolith that can't scale horizontally)
- Knowledge debt: the code works, but no one remembers why
- Dependency debt: outdated libraries, unmaintained frameworks, dead language versions
Taking on debt isn't always wrong. Problems begin when no one pays it back and it accumulates year after year.
How do you know it's time to act?
Look at measurable signals, not subjective impressions like "this code is awful":
Lead time: how long from task start to production. A simple feature taking three weeks instead of three days is a signal.
Change failure rate: what percentage of deploys breaks production or requires rollback. If every second release needs a hotfix, the system is out of control.
Estimate accuracy: if estimates regularly blow out by 3–5x, invisible dependencies are surfacing with every change.
Onboarding speed: how long it takes a new developer to ship their first meaningful task. If it takes months, you have a complexity problem.
When at least two of these indicators are degraded, it's time to act.
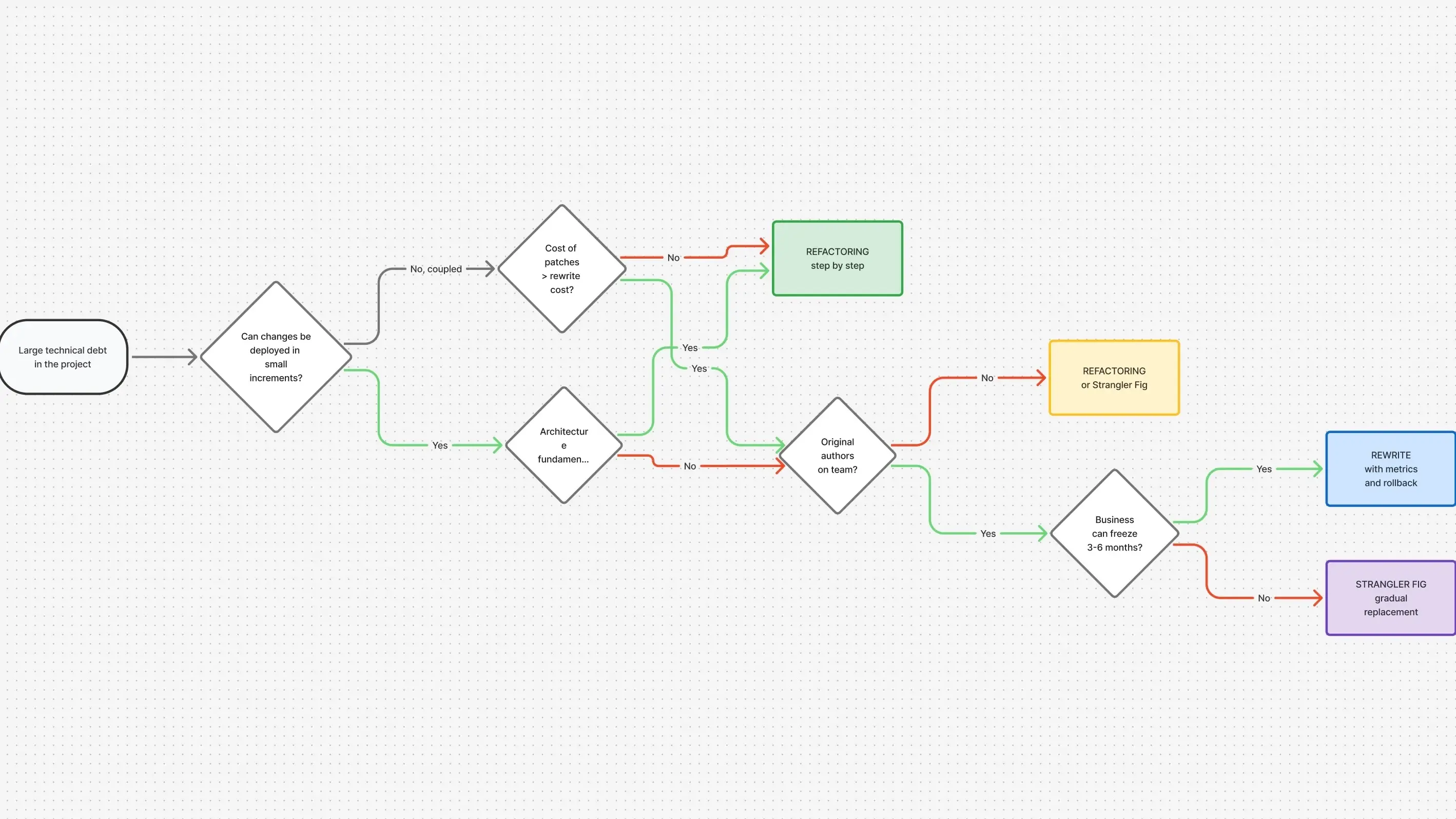
Refactoring vs rewriting: how do you decide?
Decision tree
Walk through these questions in order:
- Is the architecture fundamentally broken? (Can't scale, can't be incrementally improved?) → If yes, proceed to question 2. If no → refactor.
- Is the technology stack dead? (No security patches, end-of-life language version?) → If yes → rewrite or Strangler Fig. If no → proceed to question 3.
- Is the codebase so coupled that any change breaks ten other things? → If yes → Strangler Fig. If no → refactor.
- Can the business freeze features for 6–18 months? → If yes → rewrite may be viable. If no → Strangler Fig or refactor.
This isn't a magic formula, but it helps avoid making the decision on emotion.
When should you choose refactoring?
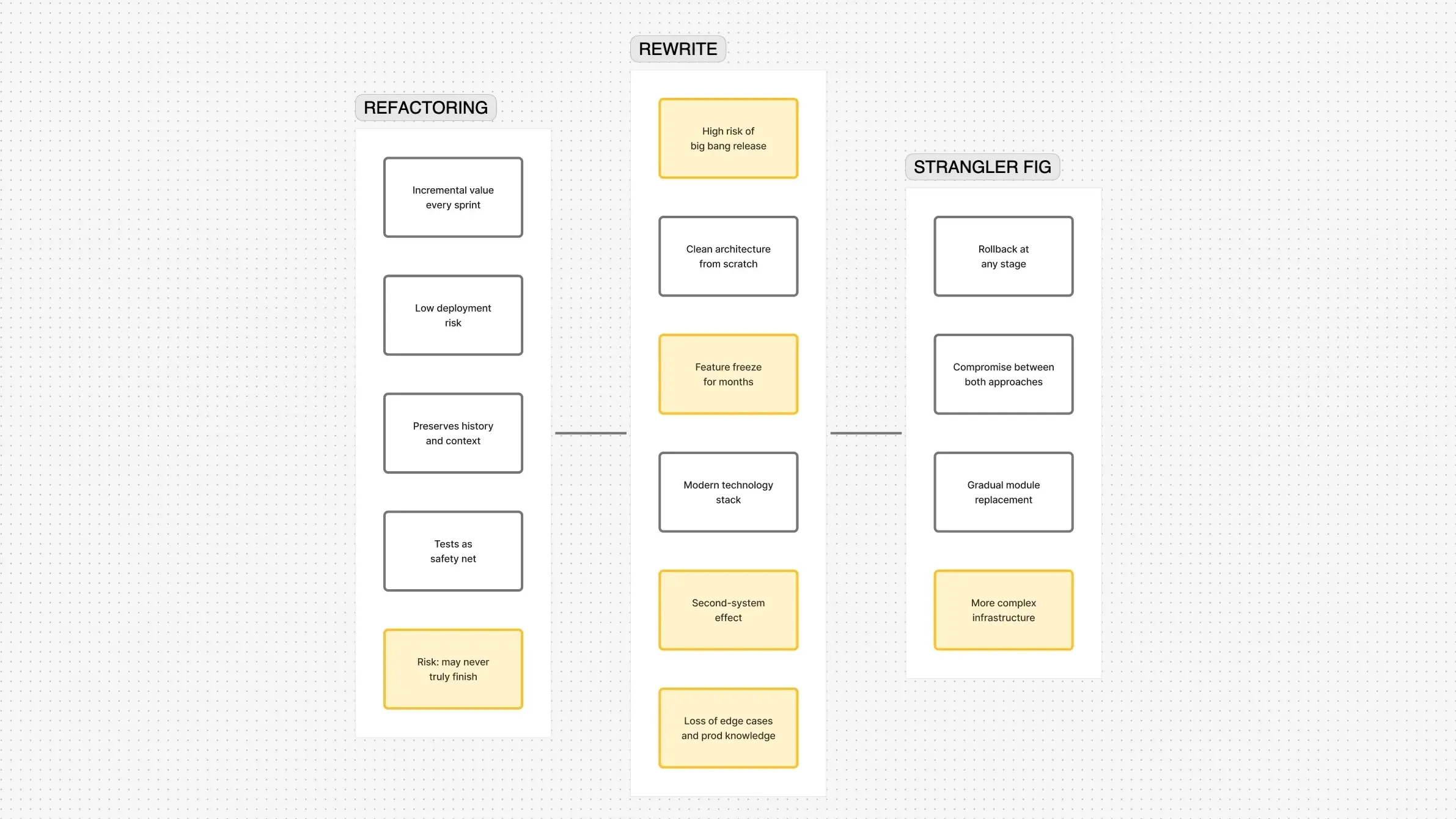
Refactoring is the gradual restructuring of code without changing behavior. You're not adding features - you're making existing code clearer, simpler, and more testable.
Choose refactoring when:
- The architecture is fundamentally sound. The problems are in specific modules, not the foundation.
- You have at least some tests: or they can be written quickly (characterization tests that capture current behavior, including bugs). Without tests, refactoring is a lottery.
- The team understands the code. Even a few people knowing why the code is the way it is makes refactoring faster and safer.
- The business can't freeze features. Refactoring allows parallel progress: new features and improvements in the same sprint.
- You can deploy in small increments. Shipping module by module means low risk and fast feedback.
In practice: take the most painful module, write tests around it, extract clean functions, remove duplication. Two weeks later the module is noticeably better. Take the next one. After a year, 60% of the codebase is significantly cleaner - with no migrations, no big bang releases, no drama.
When is a full rewrite justified?
A rewrite means building a new system from scratch in parallel with the old one, then switching users over. Higher risk - but sometimes the only correct option.
A rewrite is justified when:
- The architectural problem is fundamental. A monolith that can't scale horizontally when the business needs 50× more users. No amount of refactoring fixes this.
- The technology stack is dead. Python 2, AngularJS 1.x, a framework without security patches. This is a rewrite by default.
- Any change breaks ten other places. Sometimes the cumulative cost of a thousand patches exceeds the cost of a new system.
- You have clear acceptance metrics and realistic deadlines. Not "we'll make it better" - but "the new system must handle 10k RPS, p95 latency under 200ms, data migration tested on staging with a production copy."
- The business agrees to freeze features. If the team is expected to rewrite and keep shipping features on the old system in parallel - that's a path to doubling the debt.
- The original authors are still around. Or production incident documentation exists. Without it, the new team repeats the same mistakes in different syntax.
Non-negotiables before starting a rewrite:
- Rollback plan. What happens if four months in you won't make it? If there's no answer, don't start - this happens in more than 50% of rewrites.
- Weekly progress demos. Without them, management loses patience and kills the project.
- A concrete definition of "done." Not "when everything is beautiful" - specific, verifiable metrics.
What is the Strangler Fig pattern and when does it make sense?
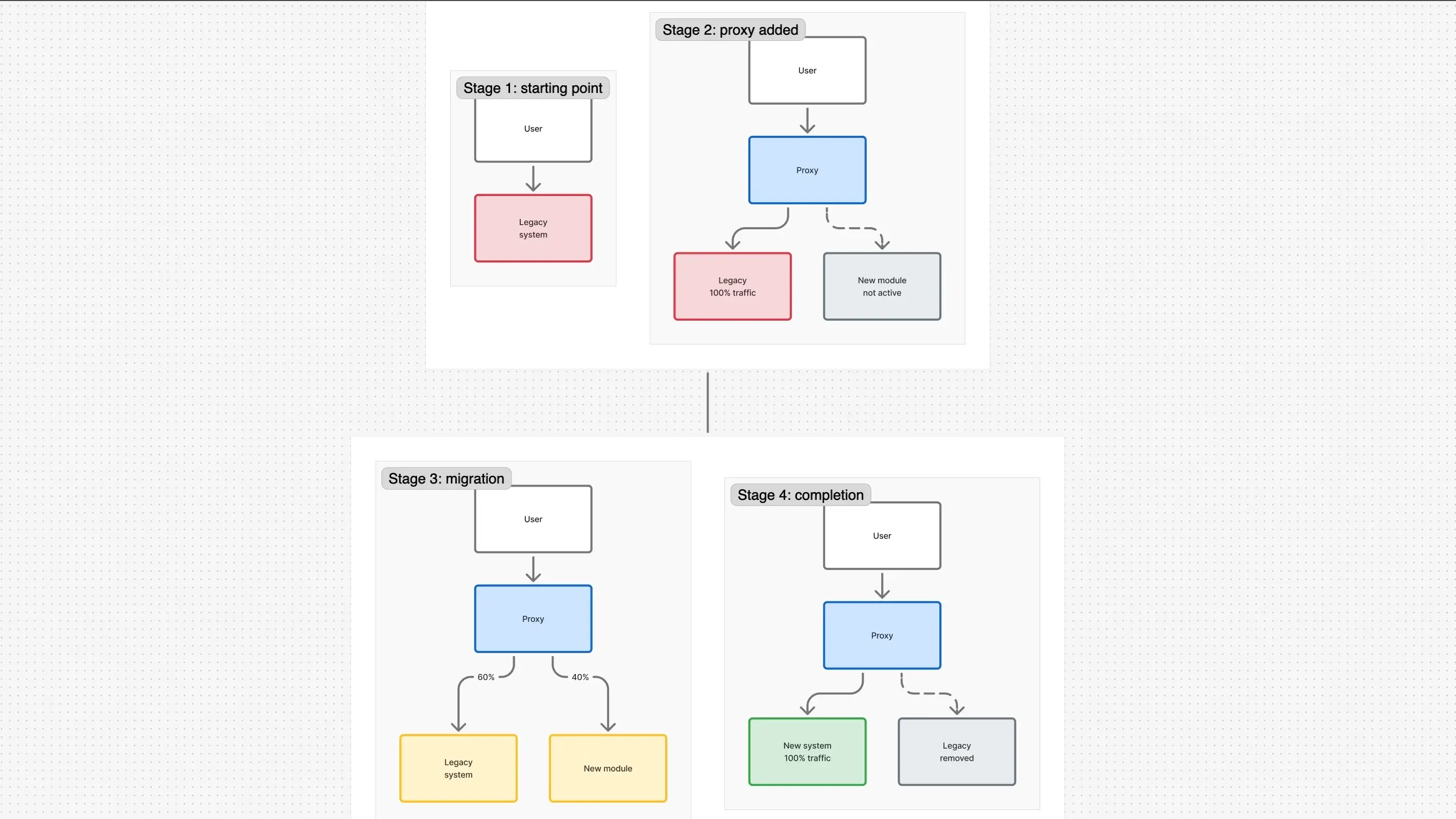
The Strangler Fig is a migration pattern where a new system gradually wraps the old one. Martin Fowler named it after a tropical tree: the fig starts growing on another tree's trunk, wraps it with roots and branches, and eventually the old tree dies inside while the fig stands in its place.
How it works in software:
- Stage 1: Legacy exists. Users hit it directly.
- Stage 2: A proxy or router is placed in front. All traffic still goes to legacy, but the architecture is now ready for migration.
- Stage 3: Migration begins. One module is rewritten; the proxy routes requests for that module to the new system. Everything else stays as it was.
- Stage 4: After months (or years), all traffic is on the new system. Legacy can be shut down.
Use Strangler Fig when:
- The architectural problem is serious, but a full rewrite is too risky
- The business can't freeze features
- The team wants to learn the new architecture gradually, without a revolution
- You need rollback capability at every stage
The Strangler Fig is often the best of both worlds: real architectural progress without the existential risk of a full rewrite.
What does a rewrite actually cost the business?
Technical discussions about refactor vs rewrite often happen between engineers, but the decision ultimately belongs to the business. Here are the key risks worth quantifying.
Budget risk: real cost is always higher than the estimate. Rule of thumb: multiply your most optimistic estimate by 3. Technical debt is a known cost - you can measure lead time today. A rewrite is an unknown cost with a meaningful chance of outright failure.
Opportunity cost: what you're NOT shipping while rewriting. In 1997, Netscape rewrote their browser from scratch. While they did, Microsoft incrementally improved Internet Explorer and captured the market. The question for the business: "How much does it cost us not to ship new features for the next 9–12 months?" - that number is often larger than the rewrite itself.
Delivery impact - by approach:
| Approach | Velocity impact | Delivery stops? |
|---|---|---|
| Refactoring | −15–25% | No |
| Rewrite | Near zero for 6–18 months | Effectively yes |
| Strangler Fig | −20–30% | No |
Risk of total failure. Refactoring rarely fails outright - at worst you end up with a somewhat better system. A rewrite can fail catastrophically: years of work, exhausted budget, no new version shipped, and the old system now even more outdated.
How to frame this for stakeholders:
- Speak in business terms: not "we have bad architecture" but "the current code makes new features take 60% longer than they should."
- Show metrics: lead time, change failure rate, onboarding time, rollback rate.
- Offer scenarios with tradeoffs, not a single recommendation.
- Demonstrate weekly progress. The business doesn't believe in "almost done in 6 months."
Refactoring vs rewriting vs Strangler Fig: comparison table
| Criterion | Refactoring | Rewrite | Strangler Fig |
|---|---|---|---|
| Deployment risk | Low | Very high | Medium |
| Time to first results | 1–2 weeks | 6–12 months | 1–3 months |
| Production knowledge preserved | Full | Partially lost | Full |
| Feature freeze required | No | Almost mandatory | Partial |
| Rollback capability | Always | Only before full switch | At every stage |
| Infrastructure cost | Unchanged | Temporarily doubled | Increased |
| Organizational complexity | Low | High | Medium |
| Fits legacy with dying stack | No | Yes | Yes |
| Fits live product with active users | Yes | Risky | Yes |
Real case study: how we chose refactoring over a full rewrite
We took over a property and building management platform for the Danish market. The stack: React and JavaScript on the frontend, Python (Django REST) on the backend, PostgreSQL. The team: 2 backend devs, 2 frontend devs, 1 fullstack - five engineers on a live product with paying customers.
Starting state:
- Almost no documentation
- Fragmentary test coverage: 60% in some places, 0% in others
- Parts written by a previous team; institutional knowledge was gone
- Some frontend components: 800+ lines mixing business logic, validation, and UI
- Backend endpoints with N+1 problems causing 30–45 second response times
The first instinct was the same one described at the start - rewrite everything. But we stopped and diagnosed honestly. Three objective factors pushed us toward refactoring:
- Production was live with real customers. A big bang migration risked something critical.
- Feature delivery couldn't stop. On a team of 5, splitting time between refactoring and delivery is realistic. Six months of feature freeze almost guarantees losing customers.
- The stack was alive. Not legacy, not dying. The problem was how the tools had been used, not the tools themselves.
How we approached it:
- One module at a time - picked the most painful, or the one with upcoming features. One 1–3 week iteration per module.
- Filled in documentation as we went: what each module does, how it connects, known limitations.
- Wrote ADRs (Architectural Decision Records) in MADR format - every significant decision captured as markdown in the repo.
- Wrote characterization tests first - pinning down current behavior, quirks and all - then refactored.
- Didn't touch modules that were working. If it did its job, we left it alone - even if the code wasn't pretty.
What improved after ~6 months:
- Time to ship features in refactored modules dropped by roughly half.
- A new developer could ship their first meaningful task in one to two weeks instead of a month.
- One N+1 endpoint went from 45-second responses to under 1 second after refactoring a single function - nothing around it touched.
- Change failure rate visibly dropped. Tests caught bugs before production.
- A major PostgreSQL version upgrade was completed with no service interruption - because the architecture wasn't being torn down, just methodically improved.
The main lesson: the initial urge to rewrite was the wrong signal. After six months, the team looked at the same codebase differently - not "tear it all down," but "this part is complex but livable, this part is a weak spot we'll improve." A much healthier position for both engineers and the business.
What are the most common mistakes when dealing with technical debt?
1. Rewriting without clear metrics. "We'll do it right" isn't a metric. Without concrete KPIs - response time, RPS, test coverage, onboarding time - you won't know when you're done.
2. Carrying "everything we didn't do in the old system" into the new one. This is the second-system effect - Fred Brooks described it in The Mythical Man-Month. The second version is almost always overengineered. Keep the scope tight.
3. Throwing out the original team. Old code is often "weird" because of a real incident that shaped it - not because the authors were bad engineers. Know the context before judging.
4. Refactoring without tests. Without tests, you can't verify your changes didn't break anything. Start with characterization tests, then refactor.
5. Long-lived feature branches. A branch that lives three months isn't a branch - it's a parallel fork. The merge will cost more than the refactor. Use Branch by Abstraction instead.
6. Assuming "terrible code" means "must rewrite." Often it means "I don't understand it yet." The urge to rewrite is usually proportional to how recently someone joined the project - after 3–6 months it often passes.
7. No rollback plan. "We've invested three months, no going back" is how rewrites turn into disasters.
8. Not showing progress to management. Teams that don't communicate movement invite panic and intervention. Weekly demos, clear milestones, visible metrics - mandatory.
Conclusion
The default is refactoring. Rewriting is an exceptional case that needs justification, not rationalization. It's only warranted when the architecture, technology stack, or scalability limits fundamentally prevent gradual improvement.
In all other cases, incremental refactoring or Strangler Fig is the better path - safer for engineering (minimal risk of breaking production) and for the business (feature delivery doesn't stop).
If a rewrite is genuinely necessary, make sure you have:
- Clear, measurable acceptance metrics
- Realistic deadlines (multiply your estimate by 3)
- Weekly progress demos for stakeholders
- A rollback plan
- Business agreement to freeze features on the old system
- At least some people from the original team
If any of these are missing, choose Strangler Fig or refactoring.
One last point: technical debt doesn't go away on its own. Teams that don't allocate time to pay it back accumulate it until the choice becomes "rewrite or shut down." Better to pay it down consistently - a little every month - than to face that choice once every five years.
Based on the practical experience of our team across projects with technical debt of varying scale - from small React frontends to Django monoliths with codebases in the millions of lines.
FAQ
Should you refactor or rewrite code?
Refactor by default. Rewriting is only justified when the architecture, technology stack, or scalability requirements make incremental improvement impossible. In all other cases, refactoring or the Strangler Fig pattern is the safer choice.
How long does refactoring a large codebase take?
Realistically, 6 months to 2 years - in parallel with regular development. That's normal. The advantage over a rewrite is that measurable improvements appear from the first weeks.
How do you measure technical debt?
Use lead time (time from task start to production), change failure rate (percentage of deploys that require rollback or hotfix), estimate accuracy, and onboarding speed. When two or more of these are degraded, debt is affecting the business.
What is the Strangler Fig pattern in software development?
A migration pattern where a new system gradually replaces the old one by routing traffic module by module. A proxy intercepts requests; as each module is rewritten, the proxy starts routing those requests to the new system. The old system "dies" gradually without a big bang cutover.
Is a rewrite justified when changing programming languages?
Yes - this is one of the clearest cases. Python 2 to Python 3, Objective-C to Swift, AngularJS to React - these are rewrites by default. Even here, the Strangler Fig pattern (migrating module by module) reduces risk significantly.
What is Branch by Abstraction?
A technique for rewriting modules without long-lived feature branches. You create an abstract interface over the old implementation, gradually build the new one behind it, then switch via feature flag - all in the main branch.
Do you need to stop feature development during refactoring?
No. That's one of refactoring's key advantages over a full rewrite. Feature velocity drops by roughly 15–25%, but delivery doesn't stop. The key is agreeing with the business that a portion of team time goes toward paying back debt - it typically pays off in 3–6 months through faster delivery.
Can you start a rewrite and switch to refactoring midway?
Technically yes, but it's psychologically difficult - the team experiences it as failure. Better not to start a rewrite if there's genuine doubt. Strangler Fig is the safer alternative.
What is technical debt in software development?
Technical debt is the accumulated cost of development shortcuts - rushed features, skipped tests, deferred architecture decisions. Like financial debt, it accrues interest: the longer it's ignored, the more it slows development. It comes in four types: code debt, architectural debt, knowledge debt, and dependency debt.
When did the term "technical debt" originate?
The term was coined by Ward Cunningham in 1992 to explain to non-technical stakeholders why software needed refactoring. The metaphor was intentional: just as financial debt has to be repaid with interest, so do technical shortcuts.
